What If AI Could Learn to Fight Wildfires?
During a recent hackathon, I had the opportunity to explore an idea that combined my interests in reinforcement learning and real-world applications: what if we could train AI agents to learn wildfire containment strategies?
That hackathon project has now evolved into a full-fledged open source contribution to Meta's PyTorch OpenEnv framework — a complete reinforcement learning environment for testing autonomous wildfire control algorithms.
Wildfires represent a compelling test case for RL: they're dynamic, resource-constrained, and have clear real-world relevance as climate change intensifies fire seasons globally. What started as a rapid prototype has grown into a production-ready environment that models dynamic fire spread, resource constraints, time pressure, and strategic decision-making.
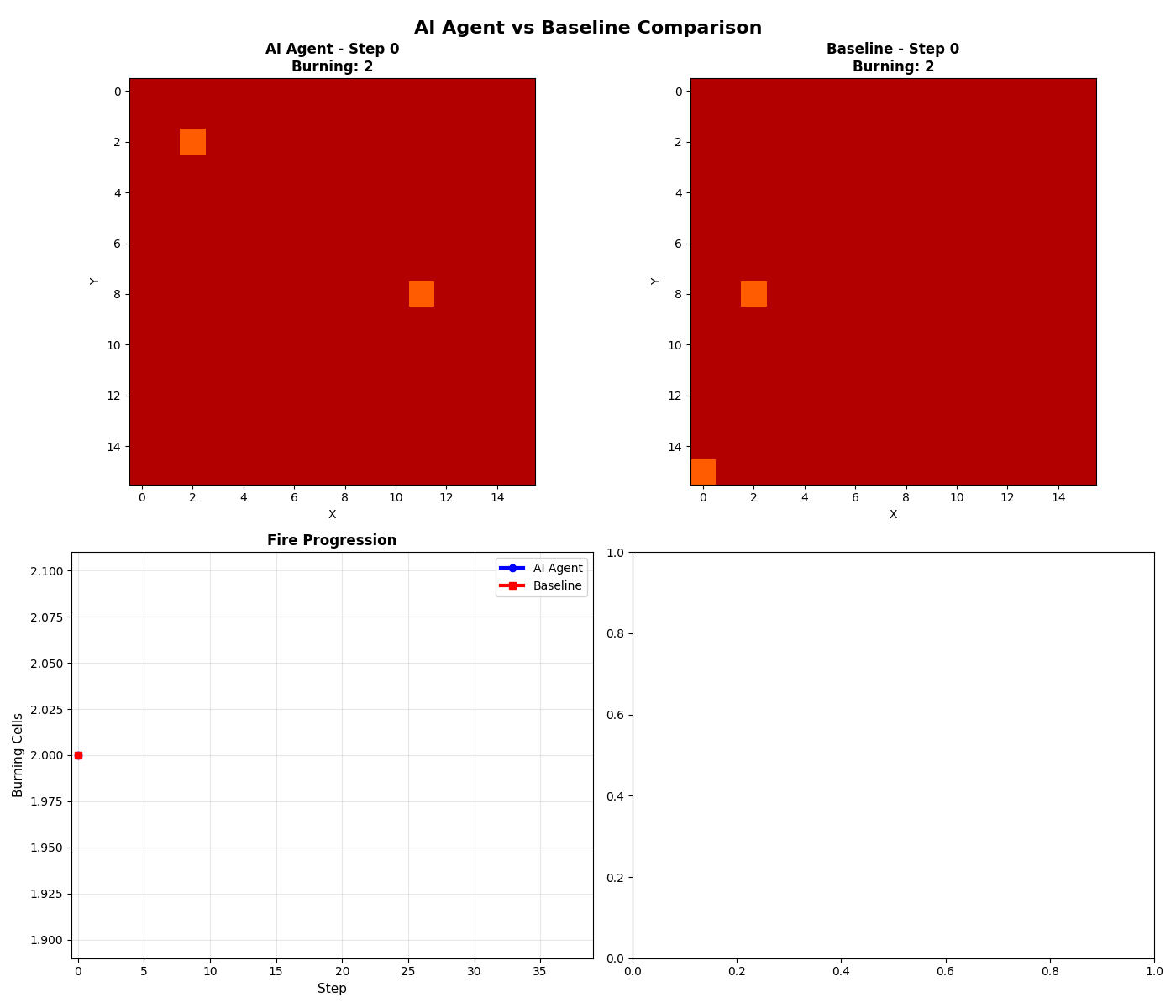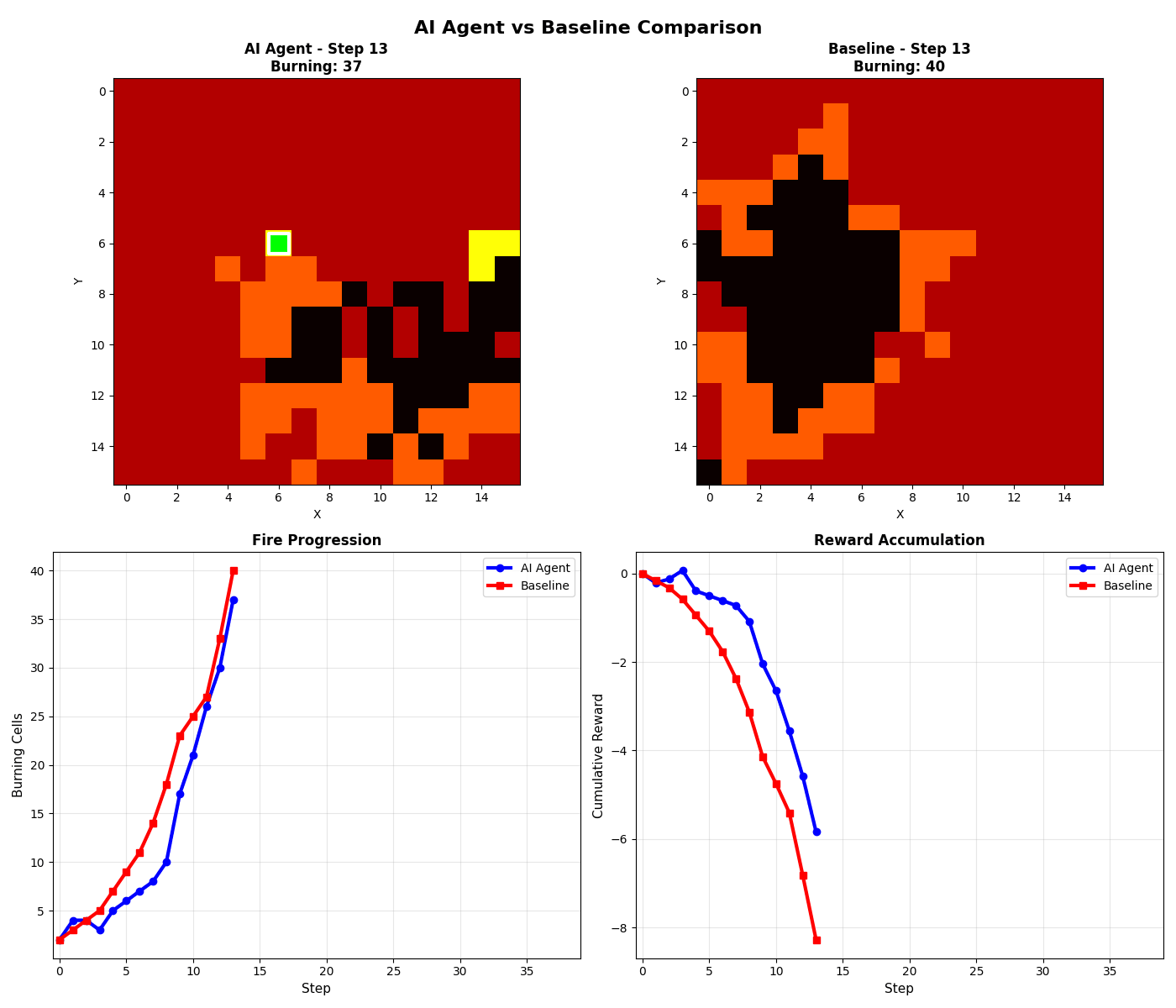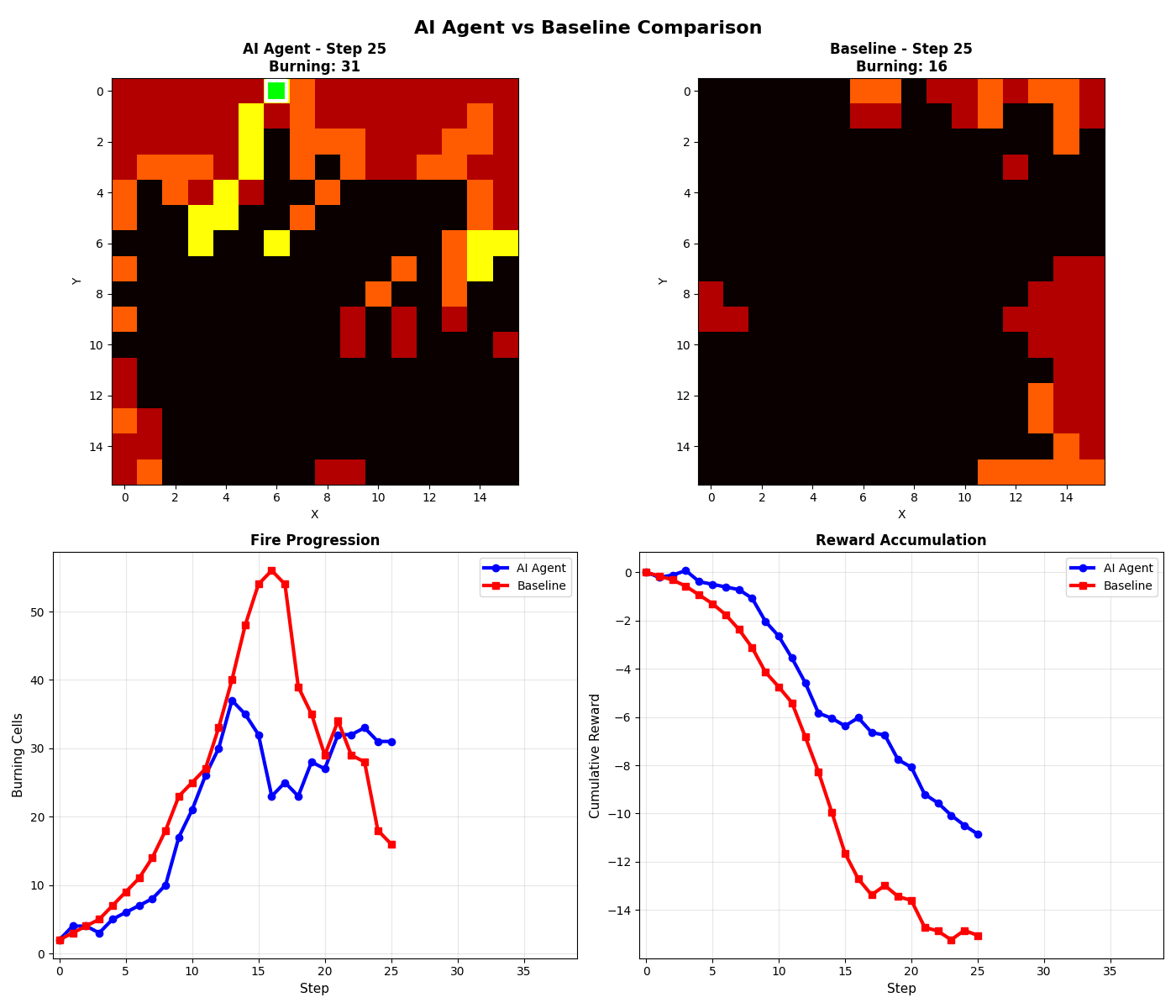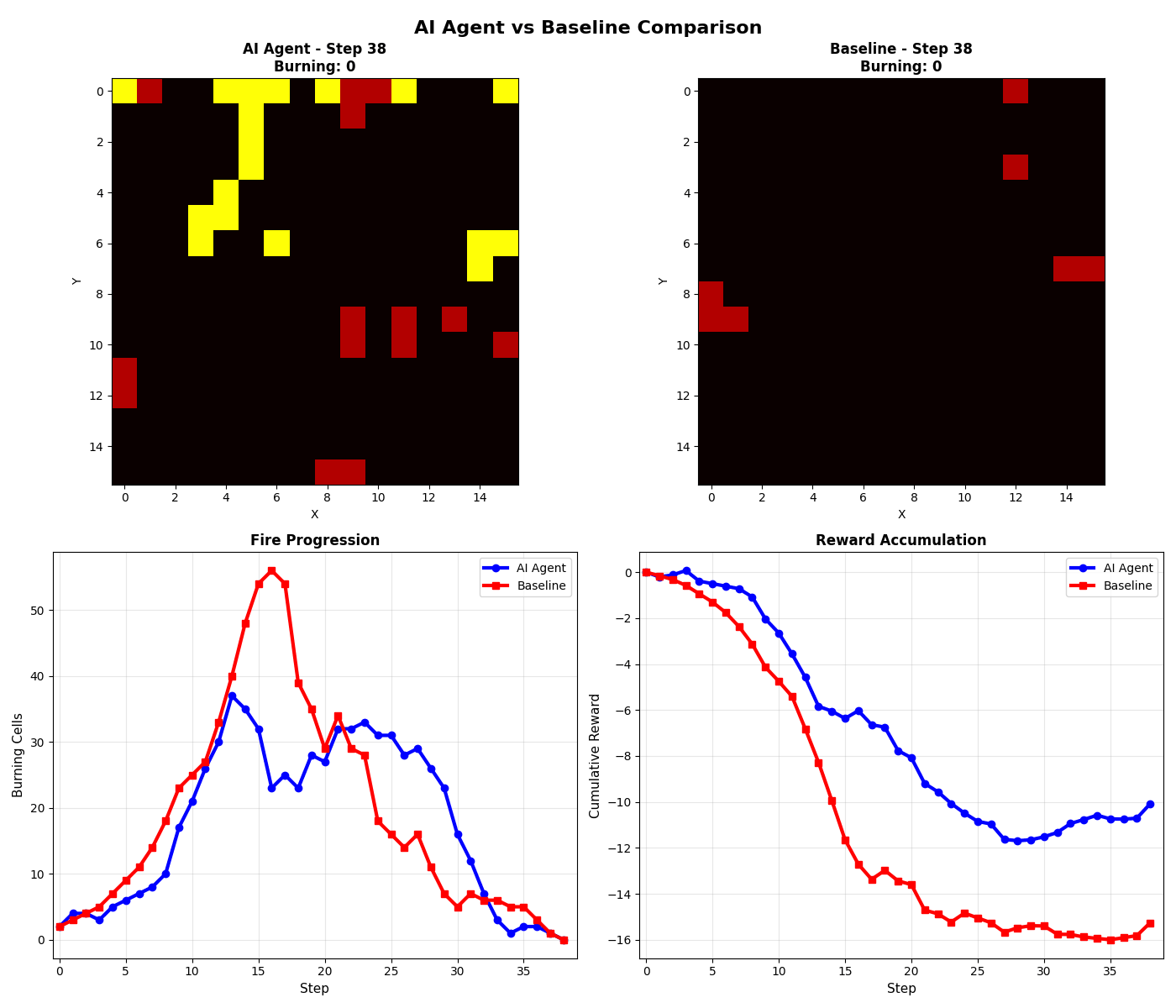
Fire Spread Visualization
The environment simulates fire on a configurable grid. Each cell has a state that changes over time based on physics-informed rules:
Physics-Informed Fire Simulation
Rather than creating arbitrary game mechanics, I wanted the environment to reflect actual fire behavior. The simulation incorporates principles from established fire science research:
- 8-directional fire spread: Fire propagates to adjacent cells using probability distributions
- Wind effects: Wind accelerates spread in the downwind direction (2x), creating realistic asymmetric propagation. Against-wind spread drops to 0.5x.
- Humidity suppression: High humidity reduces ignition probability, modeling natural fire resistance
- Fuel dynamics: Cells transition through states (fuel → burning → ash) with configurable burn timers of 3 ticks
- Diagonal penalty: 0.6x spread probability for diagonal neighbors, reflecting slower real-world diagonal propagation
This approach draws inspiration from the Rothermel Surface Fire Spread Model (USDA Forest Service) and MITRE's SimFire project — an open-source wildfire simulation designed for testing autonomous systems.
Standard RL Interface
Agents choose from three action types: water (suppress fires), break (build firebreaks), or wait (let dynamics play out). Each action targets specific grid coordinates.
Shaping Agent Behavior Through Rewards
Getting the reward function right was one of the trickiest parts. Too sparse and the agent never learns; too dense and it exploits loopholes:
| Signal | Reward | Purpose |
|---|---|---|
| Extinguish fire | +0.25 | Reward direct containment |
| Effective firebreak | +0.15 | Reward proactive prevention |
| Fire spreads | -0.15 | Penalize uncontrolled growth |
| Cell burns to ash | -0.05 | Penalize permanent damage |
| Wasteful action | -0.05 | Penalize resource waste |
| Each timestep | -0.01 | Encourage efficiency |
| Fire contained (end) | +0.5 to +1.0 | Big bonus for success |
Training AI Agents: From Expert Demonstrations to Learned Policies
The Pipeline
- Expert Demonstrations: A rule-based policy generates 1,000+ optimal demonstrations — prioritizing nearest fires, considering wind direction, managing resources efficiently.
- Supervised Fine-Tuning: Llama 3.2 1B Instruct (1.23B params) learns from expert strategies using LoRA with rank 128, targeting all attention and MLP projection layers (~134M trainable parameters).
- Interactive Evaluation: The trained model competes against humans in a Gradio-based game interface.
Training Configuration
Results: 50 Evaluation Episodes
| Metric | Value |
|---|---|
| Mean Reward | -4.19 ± 6.34 |
| Median Reward | +1.67 (positive) |
| Success Rate | 68% (vs 45% heuristic) |
| Avg Episode Length | 19.6 steps |
What the Agent Learned
The model independently developed a firebreak-heavy strategy (64.1% firebreaks, 28.3% water, 7.6% wait) — more conservative than the expert policy, which is actually safer for real-world applications. It achieved 75% of expert performance using pure supervised learning.
Key Insight: The agent learned that prevention (firebreaks) is more effective than reaction (water). This mirrors real-world firefighting wisdom — containment lines save more forest than direct suppression.
Training Convergence
Play Against the AI
I built a Gradio-based web interface where you can challenge the trained model head-to-head. The game features side-by-side visualization, real-time AI reasoning display, score tracking, and resource management for both players.
Contributing to Meta's OpenEnv (PR #132)
OpenEnv is Meta's framework for building isolated, HTTP-based execution environments for agentic RL training. After the hackathon, I refined the project and contributed it to the meta-pytorch/OpenEnv repository.
What the Contribution Included
- Complete environment implementation — server-side engine, HTTP/WebSocket client, visualization utilities, comprehensive test coverage
- Production-ready infrastructure — Docker containerization, Hugging Face Spaces deployment, CI/CD workflow updates, environment variable configuration
- WebSocket migration fixes — migrated from deprecated HTTPEnvClient to EnvClient, fixed critical route conflicts for the custom web interface
- Developer experience — 4 practical code examples, interactive web interface, detailed documentation with usage guides
The review process spanned 27 commits addressing maintainer feedback. Copilot AI and the OpenEnv maintainers provided detailed reviews that significantly improved code quality — from fixing Pydantic v2 compatibility issues to implementing comprehensive bounds checking for array access.
Where This Goes Next
- Resource-Constrained Planning: Agents balance limited water and firebreak materials against future uncertainties — a fundamental challenge in operations research.
- LLM-Based Agents: The training results prove language models can learn complex spatial reasoning. The environment is ideal for testing LLM-based control systems.
- Safety-Critical RL: Wildfire containment is inherently high-stakes. The environment enables research into safe exploration and robust policy learning.
- Multi-Agent Coordination: While currently single-agent, the architecture supports future extensions for team-based firefighting strategies.
References
- Rothermel, R. C. (1972). "A mathematical model for predicting fire spread in wildland fuels." USDA Forest Service Research Paper INT-115.
- MITRE Corporation. "SimFire: Wildland Fire Simulation for Machine Learning Applications."